https://www.notion.so/develothy/Elastic-Search-b17cc231b4d34b79a912a126067fb757
Elastic Search
Elasticsearch는 Apache Lucene( 아파치 루씬 ) 기반의 Java 오픈소스 분산 검색 엔진
www.notion.so
GitHub - Develothy/elasticsearch: elasticsearch study
Elastic Search
Elasticsearch는 Apache Lucene( 아파치 루씬 ) 기반의 Java 오픈소스 분산 검색 엔진
Elasticsearch는 방대한 양의 데이터를 신속하게, 거의 실시간( NRT, Near Real Time )으로 저장, 검색, 분석할 수 있다.
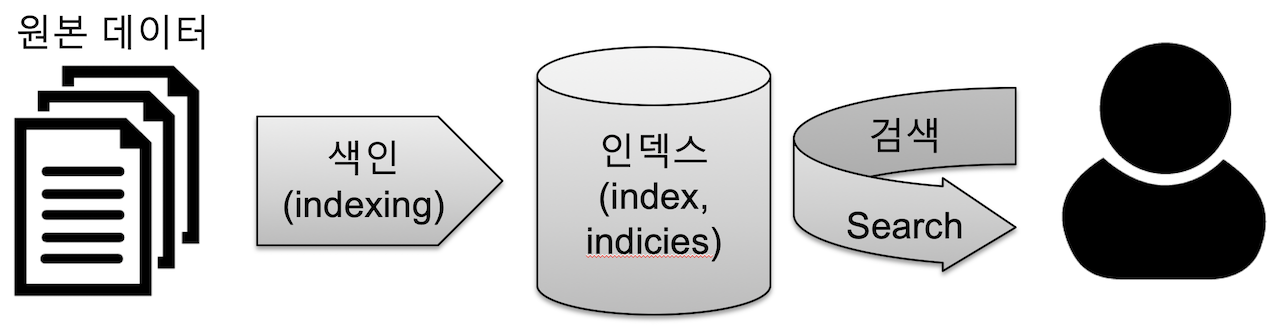
- indexing(색인)
- 데이터가 검색될 수 있는 구조로 변경하기 위해 원본 문서를 검색어 토큰들으로 변환하여 저장
- 데이터가 검색될 수 있는 구조로 변경하기 위해 원본 문서를 검색어 토큰들으로 변환하여 저장

- index(indeces)
- 색인 과정을 거친 결과물 또는 색인된 데이터가 저장되는 저장소
- 단일 데이터 단위를 document라고 하고 이를 모아놓은 집합이 index
- shard라는 단위로 분리되고 각 node에 분산되어 저장
- shard는 루씬의 단일 검색 인스턴스
- 색인 과정을 거친 결과물 또는 색인된 데이터가 저장되는 저장소
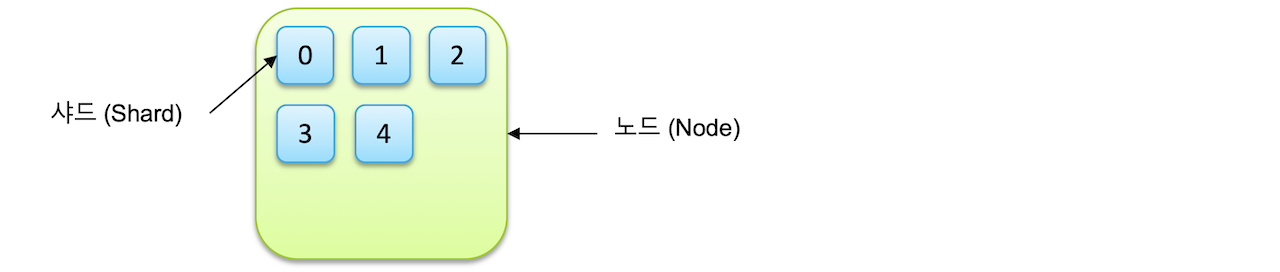
- cluster > node > index > shard, replica
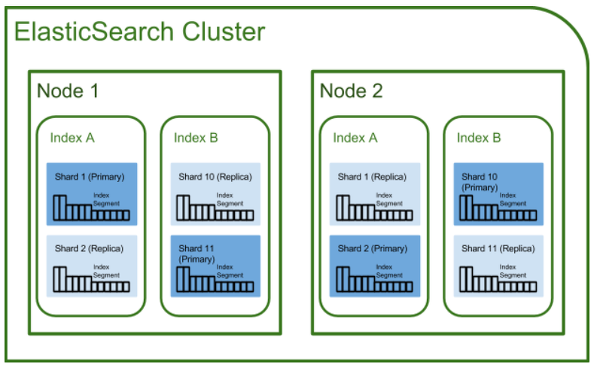
- 설명
- 클러스터( cluseter )
- 서로 다른 클러스터는 데이터의 접근, 교환을 할 수 없는 독립적인 시스템으로 유지되며, 여러 대의 서버가 하나의 클러스터를 구성할 수 있고, 한 서버에 여러 개의 클러스터가 존재할수도 있음.
클러스터란 Elasticsearch에서 가장 큰 시스템 단위를 의미로, 최소 하나 이상의 노드로 이루어진 노드들의 집합
- 서로 다른 클러스터는 데이터의 접근, 교환을 할 수 없는 독립적인 시스템으로 유지되며, 여러 대의 서버가 하나의 클러스터를 구성할 수 있고, 한 서버에 여러 개의 클러스터가 존재할수도 있음.
- 노드( node )
- Elasticsearch를 구성하는 하나의 단위 프로세스를 의미.
그 역할에 따라 Master-eligible, Data, Ingest, Tribe 노드로 구분
- Elasticsearch를 구성하는 하나의 단위 프로세스를 의미.
- 인덱스( index ) / 샤드( Shard ) / 복제( Replica )
- Elasticsearch에서 index는 RDBMS에서 database와 대응
또한 shard와 replica는 Elasticsearch에만 존재하는 개념이 아니라, 분산 데이터베이스 시스템에도 존재하는 개념 - 샤딩( sharding )은 데이터를 분산해서 저장하는 방법을 의미
즉, Elasticsearch에서 스케일 아웃을 위해 index를 여러 shard로 쪼갠 것
기본적으로 1개가 존재하며, 검색 성능 향상을 위해 클러스터의 샤드 갯수를 조정하는 튜닝을 하기도 한다. - replica는 또 다른 형태의 shard라고 할 수 있다.
노드를 손실했을 경우 데이터의 신뢰성을 위해 샤드들을 복제…
따라서 replica는 서로 다른 노드에 존재할 것을 권장
- Elasticsearch에서 index는 RDBMS에서 database와 대응
- 클러스터( cluseter )

Elastic Search 특징
- 저장 방식
- Elastic Search
| text | document |
| --- | --- |
| rothy | doc1, doc2 |
| lala | doc1, doc3 |
- 관계형 DB
| document | context |
| --- | --- |
| doc1 | "class” : { “name” : “database”, “professor”:”rothy”} |
| doc3 | "class” : { “name” : “database”, “professor”:”lala”} |
- Scale out
- 샤드를 통해 규모가 수평적으로 늘어날 수 있음
- 고가용성
- Replica를 통해 데이터의 안정성을 보장
- Schema Free
- Json 문서를 통해 데이터 검색을 수행하므로 스키마 개념이 없음
- Restful
- 데이터 CURD 작업은 HTTP Restful API를 통해 수행하며, 각각 아래처럼 대응
| Data CRUD | Elasticsearch Restful |
| --- | --- |
| SELECT | GET |
| INSERT | PUT |
| UPDATE | POST |
| DELETE | DELETE |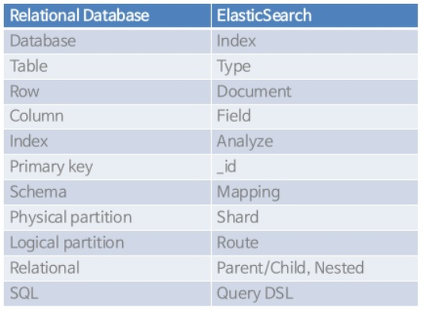
Elastic Search 컨테이너 실행 - Docker 🐬
- Docker run
- nori 설정은 아래
#도커 이미지 확인 docker images #실행 docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" c5ac99164e4b #docker imageId #실행 확인 docker ps
- Docker-compose.yml
run시 지정했던 옵션도 설정할 수 있고, 함께 사용할 nori, kivana도 묶을 수 있다- image : 컨테이너 실행을 위한 실행 가능한 파일시스템과 필요한 구성요소를 포함하는 패키지
docker images로 확인 가능
- app내에서 nori를 사용한 설정을 하였더니 검색 시 exception 떠서 command설정을 했다!
- 컨테이너 안에서 nori를 설치하고 초기설정 수행, 서버 실행한다
- image : 컨테이너 실행을 위한 실행 가능한 파일시스템과 필요한 구성요소를 포함하는 패키지
version: '3'
services: elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.17.4
container_name: elasticsearch
environment: - discovery.type=single-node
- node.name=elasticsearch
- cluster.name=docker-cluster
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms1g -Xmx1g"
command:
> bash -c " bin/elasticsearch-plugin install analysis-nori;
exec /usr/local/bin/docker-entrypoint.sh"
ulimits: memlock: soft: -1 hard: -1
volumes: - esdata:/usr/share/elasticsearch/data
ports:
- 9200:9200 #local:container
- 9300:9300
kibana:
image: docker.elastic.co/kibana/kibana:7.17.4
container_name: kibana
ports:
- 5601:5601
environment: ELASTICSEARCH_URL: http://elasticsearch:9200
depends_on: - elasticsearch
volumes: esdata: driver: local
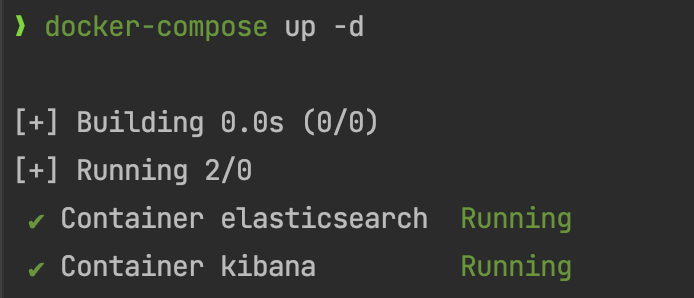
- 실행
- docker-compose up -d
-d: "백그라운드(background) 모드" 또는 "데몬(daemon) 모드”- 컨테이너가 동작하는 동안 로그를 지속적으로 표시하지 않고도 터미널에서 다른 명령을 입력 가능.
-d옵션 없이 명령을 실행하면 컨테이너가 포그라운드(foreground) 모드로 실행되며, 컨테이너의 로그가 터미널에 실시간으로 표시
- 컨테이너가 동작하는 동안 로그를 지속적으로 표시하지 않고도 터미널에서 다른 명령을 입력 가능.
- docker에서 확인
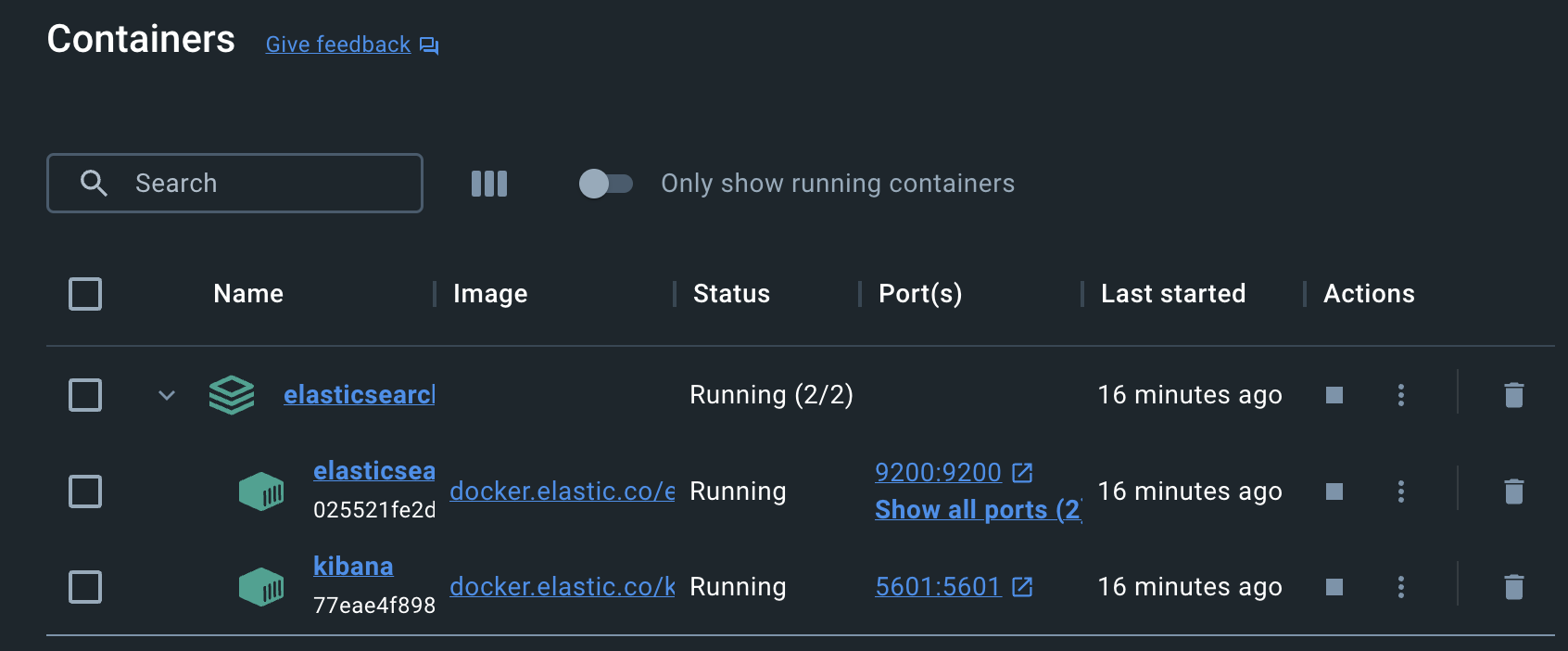
- 접속 확인
{ "name": "9de634a682bc", "cluster_name": "docker-cluster", "cluster_uuid": "7nfXYwuRRNS32xTjOPwEPQ", "version": { "number": "7.17.4", "build_flavor": "default", "build_type": "docker", "build_hash": "79878662c54c886ae89206c685d9f1051a9d6411", "build_date": "2022-05-18T18:04:20.964345128Z", "build_snapshot": false, "lucene_version": "8.11.1", "minimum_wire_compatibility_version": "6.8.0", "minimum_index_compatibility_version": "6.0.0-beta1" }, "tagline": "You Know, for Search" }Elastick Search 테스트 해보기 - Postman
인덱스, 도큐먼트 생성 및 수정
- [POST]
{indexName}/_doc/{documentId}- 수정은 [PUT]
- request
{ "name":"Woorim Lee", "message":"Hello ElasticSearch" }
- response
- { "_index": "my_index", "_type": "_doc", "_id": "1", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 0, "_primary_term": 1 }
인덱스, 도큐먼트 삭제
- [DELETE]
{indexName} - [DELETE]
{indexName}/_doc/{documentId}- response
- { "acknowledged": true }
- response
인덱스 전체 조회
- [GET]
{indexName}/_search
검색
- [GET]
{indexName}/_search?p=lee- response
- { "took": 77, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 1, "relation": "eq" }, "max_score": 0.2876821, "hits": [ { "_index": "my_index", "_type": "_doc", "_id": "1", "_score": 0.2876821, "_source": { "name": "Woorim Lee", "message": "Hello ElasticSearch" } } ] } }
- response
검색 조건 지정
- name 필드에서 검색을 하겠다
- requsest
- { "query": { "match": { "name":"Lee" //키워드 } } }
- requsest
- 출력 필드를 지정한 검색
- request
- { "fields":["name"], "query": { "match": { "name":"Lee" //키워드 } } }
- request
Elastic Search 사용하기 - Java
검색
@Autowired
private RestHighLevelClient restHighLevelClient;
private static final String MY_INDEX = "my_index";
private static final String DOC_TYPE = "_doc";
public String getSearchResult(String field, String q) throws IOException {
SearchRequest searchRequest = new SearchRequest(MY_INDEX)
.source( new SearchSourceBuilder()
.query(QueryBuilders.matchQuery(field, q))
.sort(DOC_TYPE, SortOrder.ASC));
// 인덱스 확인
GetIndexRequest getIndexRequest = new GetIndexRequest(MY_INDEX);
boolean indexExists = restHighLevelClient.indices().exists(getIndexRequest, RequestOptions.DEFAULT);
if (!indexExists) {
return "인덱스 없음~";
}
// 검색 요청 실행
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
return response.toString();
}- RestHighLevelClient
- Elasticsearch와 통신한다. 기본적으로 HTTP 프로토콜로 9200포트 통신~
- 아래와 동일한 기본 값을 가지고 있다.
- Elasticsearch와 통신한다. 기본적으로 HTTP 프로토콜로 9200포트 통신~
@Autowired private RestHighLevelClient restHighLevelClient = new RestHighLevelClient( RestClient.builder(new HttpHost("localhost", 9200, "http")));- Elasticsearch의 REST API를 추상화. Elasticsearch 클러스터와 상호작용하기 위한 편리한 메서드와 기능을 제공
search(),indices()등- deprecated 됐길래 RestClient를 사용했더니, 이건 저수준 클라이언트라 지원되지 않는 기능 많다..
- SearchRequest
source(SearchSourceBuilder): 검색에 필요한 세부사항 정의- SearchSourceBuilder
- /_search 엔드포인트와 유사
- body로 지정할 요청을 쿼리로 빌드해줌
query()메서드를 사용하여 검색에 사용할 쿼리를 설정match,term,bool,range등으로 검색 조건을 지정할 수 있음
postFilter(),sort(), paging(from(),size())
- /_search 엔드포인트와 유사
- SearchSourceBuilder
- SearchRequest→ SearchResponse, IndexRequest → IndexResponse
- 각 목적에 따라 요청, 응답 객체를 생성
- indices : 인덱스 지정
- source : 검색 또는 추가 소스 설정
- preference : 검색 우선순위 지정
- 동일한 선호도 값을 가진 요청은 동일한 샤드에서 실행 보장
- 여러 노드와 샤드로 구성된 elastic 클러스터에서 검색 요청이 전달되면, 요청은 여러 샤드에 분산되서 실행될 수 있는데,,,(일반적으로 샤드를 고르게 분산처리)
preference를 설정하면 동일한 샤드로 라우팅해 결과의 일관성을 유지한다고 함… - 사용 예시
- 데이터의 일관성 유지: 여러 개의 검색 요청이 동일한 샤드에서 실행되어 일관성 있는 결과를 얻고자 할 때
- 캐싱 활용: 선호도를 설정하면 Elasticsearch는 해당 선호도 값을 가진 검색 결과를 캐싱하고, 동일한 선호도 값을 가진 다른 요청이 해당 캐시를 활용
- 여러 노드와 샤드로 구성된 elastic 클러스터에서 검색 요청이 전달되면, 요청은 여러 샤드에 분산되서 실행될 수 있는데,,,(일반적으로 샤드를 고르게 분산처리)
- 동일한 선호도 값을 가진 요청은 동일한 샤드에서 실행 보장
- 각 목적에 따라 요청, 응답 객체를 생성
SearchRequest searchRequest = new SearchRequest("my_index"); searchRequest.preference("userService");
인덱스 생성하기
- 아래 Nori 설치 후 진행~
Nori 형태소 분석기
형태소 단위로 분석하여 단어, 조사, 어근 등의 형태소로 분리.
이렇게 분리된 형태소는 Elasticsearch에서 색인 생성 시에 사용되고, 검색 시에도 분석된 형태소에 기반하여 정확한 결과를 반환하도록 도와준다~!
- docker-compose.yml으로 docker up 했을 경우 생략!
- Nori 설치 커맨드 있음. 인덱스 생성시 analyzer로 nori를 지정.
- (docker run 할때만)
Nori 설치하기
나는 docker로 실행했기 때문에
docker 컨테이너를 실행시키고 접속하여 Nori 플러그인을 설치 해준다.
# 실행
docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" c5ac99164e4b
# 컨테이너 접속
docker exec -it elasticsearch /bin/bash
# 컨테이너 내부에서 Nori 설치
./bin/elasticsearch-plugin install analysis-nori
# 컨테이너 나가기
exit
# 컨테이너 재시작
docker restart elasticsearch
# 실행중인 컨테이너 확인~
docker ps- 컨테이너 내부에서 실행할때
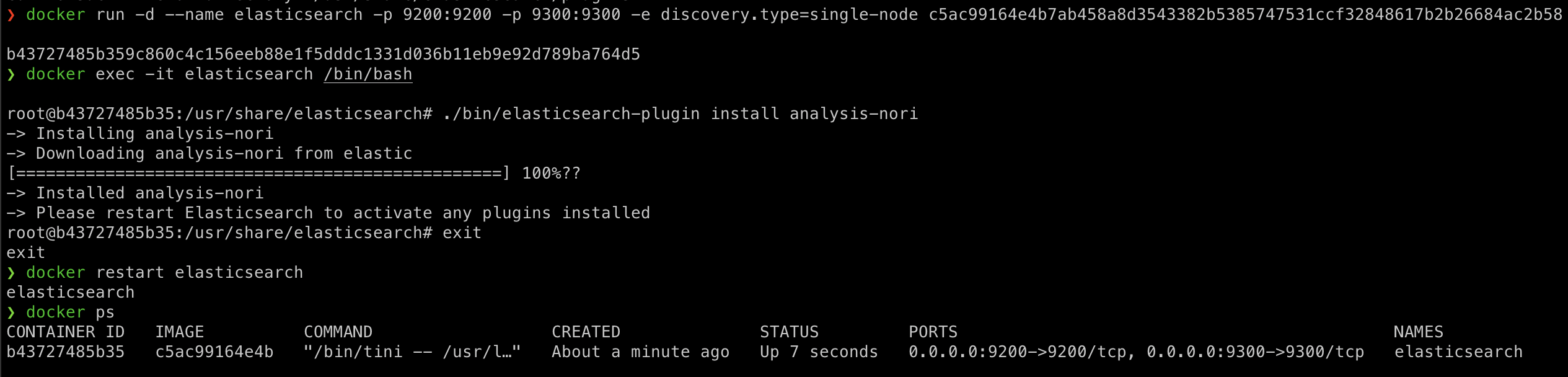
- Nori가 잘 설치됐는지 확인~~
- http://localhost:9200/_cat/plugins?v오예 😂 😂 😂 😂 😂 😂

Nori 세팅하기 - index 생성 - Java
- index 생성 - 이때 분석기와 매핑을 지정해준다!
public String createIndexWithNori(String indexName) throws IOException {
CreateIndexRequest createIndexRequest = new CreateIndexRequest(indexName)
.settings(Settings.builder()
.put("index.analysis.analyzer.default.type", "nori")
.put("index.analysis.analyzer.default.decompound_mode", "mixed")
.put("index.analysis.analyzer.default.stopwords", "_korean_")
.build());
XContentBuilder mappingBuilder = XContentFactory.jsonBuilder()
.startObject()
.startObject("properties")
.startObject("message")
.field("type", "text")
.field("analyzer", "nori")
.endObject()
.endObject()
.endObject();
createIndexRequest.mapping(mappingBuilder);
CreateIndexResponse createIndexResponse = restHighLevelClient.indices().create(createIndexRequest, RequestOptions.DEFAULT);
return createIndexResponse.toString();
}- CreateIndexRequest
- 이 객체로 index를 생성할 때 setting을 사용해
analyzer를 Nori로 지정decompound_mode는 복합명사를 분해하는 방법이라고 한다…;;stopwords한국어로 설정~ 이제 한글 검색도 된다
- 이 객체로 index를 생성할 때 setting을 사용해
- XContentBuilder
- Elasticsearch에 바디를 보내듯이 Json 구조로 매핑을 정의할 수 있다…
- 아래처럼 작성한 효과
- “message” 필드가 Nori를 사용해 검색되도록 지정했다
{ "properties": { "message": { "type": "text", "analyzer": "nori" } } }
- 아래처럼 작성한 효과
- Elasticsearch에 바디를 보내듯이 Json 구조로 매핑을 정의할 수 있다…
🔎 message 필드의 ‘우림’ 검색 결과
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "my_index",
"_type": "_doc",
"_id": "2",
"_score": null,
"_source": {
"name": "우림",
"message": "이우림 우림 이우 이 우 림"
},
"sort": [
5
]
},
{
"_index": "my_index",
"_type": "_doc",
"_id": "8",
"_score": null,
"_source": {
"name": "rothy",
"message": "rothy우림rothy"
},
"sort": [
7
]
}
]
}
}😭
잘된다…!!
키바나
http://localhost:5601/
'DEV Heart' 카테고리의 다른 글
| 메세징! Kafka vs SQS (0) | 2026.03.17 |
|---|---|
| Object랑 T로 받았을떄 무슨 차이야? (2) | 2025.06.30 |
| javax.validation @어노테이션 (0) | 2021.12.27 |
| 초간단 Spring 프로젝트 생성 + dependencies 추가 (0) | 2021.12.20 |
| [Spring Boot, JPA] 프로젝트 구조 controller, domain, service, web (0) | 2021.10.25 |

